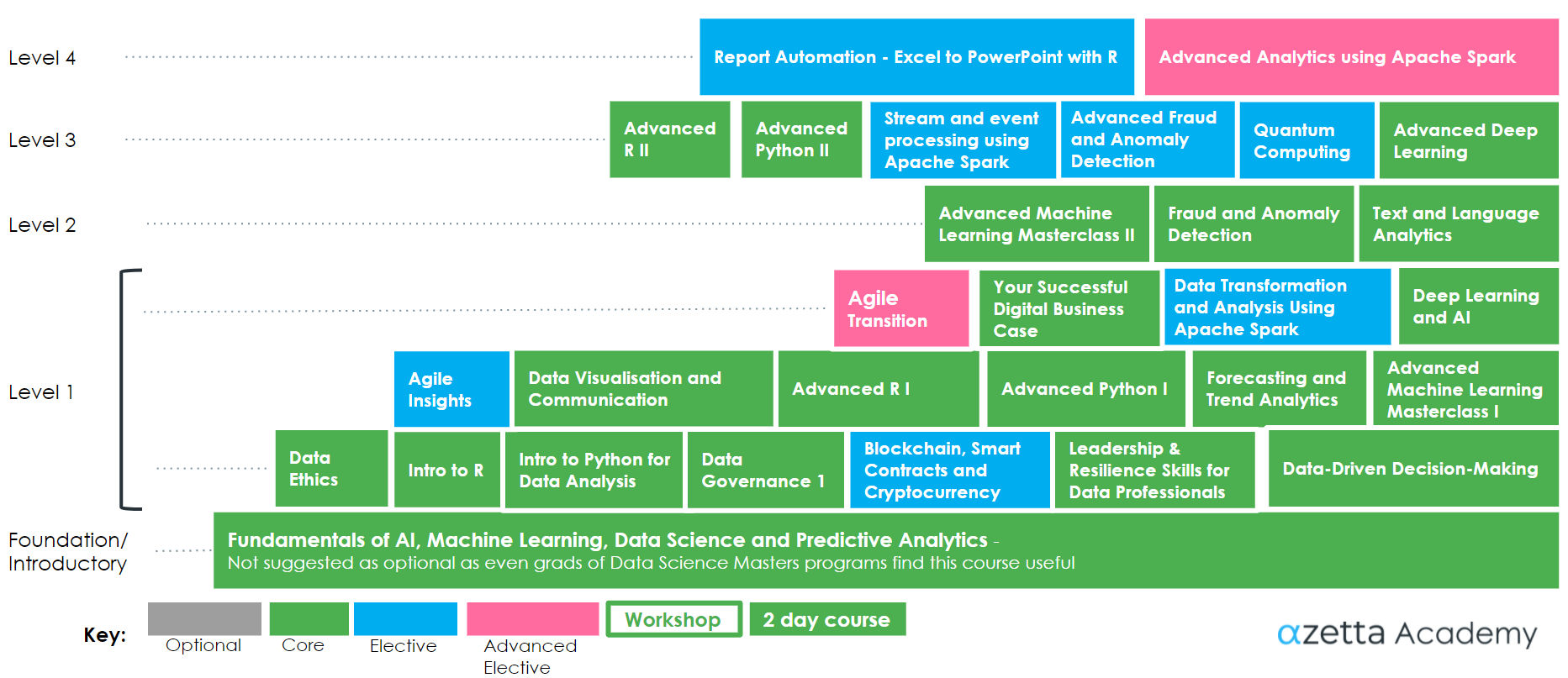
Data Science Curriculum
Our Data Science Curriculum is comprehensive in its coverage of the many topics in the field. We offer starting points for all levels – from raw beginner to expert. The curriculum is designed by Dr Eugene Dubossarsky, our Chief Data Scientist.
Why we’re different
AlphaZetta’s workshops and short courses are like none other offered in universities, online or by private providers. Our data science classes in particular are aimed at providing clients not just with the false confidence of learning a process – but the real power of the underlying concepts – allowing them to confidently practice, manage, promote and risk assess data science.
The data science curriculum aims to leave trainees with an intuition, an instinct for data science. As our lead trainer Eugene Dubossarsky likes to put it: “many courses teach data science like teaching people to memorise and recite poetry in a language they do not understand”. AlphaZetta’s aim is to give people the gift of understanding the language of data science, but taught in an intuitive, accessible way, keeping formulae and mathematics to a bare minimum and taking an innate, visual approach.
Contact us today to discuss how our Data Science Curriculum could be tailored for your organisation.
{kind=link}
*Contact us for schedule and course details
Report Automation – Excel to PowerPoint with R
Report automation can deliver powerful, time-saving results. This course teaches analytics professionals to automate the creation of PowerPoint packs from input Excel workbooks using R. Time is allotted for students to implement techniques taught so that, by the end of the course, students will have wrangled input data, created plots and tables, defined a PowerPoint template, and built a sample set of slides.
Data Visualisation and Communication
This course prepares data analytics professionals to communicate analytics results to business audiences, in a business context while being mindful of the skills, incentives, priorities and psychology of the audience. It also equips analysts [...]
Intro to R (+ data visualisation)
This R training course will introduce you to the R programming language, teaching you to create functions and customise code so you can manipulate data and begin to use R self-sufficiently in your work. R is the world’s most popular data mining and statistics package. It’s also free, and easy to use, with a range of intuitive graphical interfaces.
Intro to Python for Data Analysis
Python is a high-level, general-purpose language used by a thriving community of millions. Data-science teams often use it in their production environments and analysis pipelines, and it’s the tool of choice for elite data-mining competition winners and deep-learning innovations. This course provides a foundation for using Python in exploratory data analysis and visualisation, and as a stepping stone to machine learning.
Fundamentals of AI, Machine Learning, Data Science and Predictive Analytics
This course is an intuitive, hands-on introduction to ai, data science and machine learning, it's your artificial intelligence 101. The training focuses on fundamentals and key skills, leaving you with a deep understanding of the core concepts of ai and data science and even some of the more advanced tools used in the field. The course does not involve coding, or require any coding knowledge or experience. As our leading course, it has transformed the artificial intelligence (AI), machine learning (ML) and data science practice of the many managers, sponsors, key stakeholders, entrepreneurs and beginning data analytics and data science practitioners who have attended it.
Data Governance I
This two day course provides an informed, realistic and comprehensive foundation for establishing best practice data governance in your organisation. Suitable for every level from CDO to executive to data steward, this highly practical course will equip you with the tools and strategies needed to successfully create and implement a data governance strategy and roadmap.
Data-Driven Decision-Making
The Data-Driven Decision-Making course is for executives and managers who want to leverage analytics to support their most vital decisions and enable better decision-making at the highest levels. It empowers senior executives with skills to make more effective use of data analytics. It covers contexts including strategic decision-making and shows attendees ways to use data to make better decisions. Attendees will learn how to receive, understand and make decisions from a range of analytics methods, including visualisation and dashboards. They will also be taught to work with analysts as effective customers.
Leadership and Resilience Skills for Data Professionals
Many people today have been developed emotionally and mentally for an era that no longer really exists. This has created a critical soft-skills gap between current workforce ability and business requirements today. In this course participants learn to ‘readapt’ their soft skills so that they are aligned with a thriving 21st century business. They are also given a simple framework from which to continue the self-development so that the training instigates sustainable change.
Data Governance II
This one day course builds on the foundation of Data Governance I, and dives deeper into selected areas that are designed to provide the most practical and real-world applications of data governance. It includes the change management journey to the “data-driven” organisation, and implications of the necessity of model governance in the context of data science, AI/ML initiatives and RPA/IPA .
Advanced Analytics Using Apache Spark
With big data expert and author Jeffrey Aven. The third module in the “Big Data Development Using Apache Spark” series, this course provides the practical knowledge needed to perform statistical, machine learning and graph analysis operations at scale using Apache Spark. It enables data scientists and statisticians with experience in other frameworks to extend their knowledge to the Spark runtime environment with its specific APIs and libraries designed to implement machine learning and statistical analysis in a distributed and scalable processing environment.
Fraud and Anomaly Detection
This course presents statistical, computational and machine-learning techniques for predictive detection of fraud and security breaches. These methods are shown in the context of use cases for their application, and include the extraction of business rules and a framework for the inter-operation of human, rule-based, predictive and outlier-detection methods. Methods presented include predictive tools that do not rely on explicit fraud labels, as well as a range of outlier-detection techniques including unsupervised learning methods, notably the powerful random-forest algorithm, which can be used for all supervised and unsupervised applications, as well as cluster analysis, visualisation and fraud detection based on Benford’s law. The course will also cover the analysis and visualisation of social-network data. A basic knowledge of R and predictive analytics is advantageous.
Data Transformation and Analysis Using Apache Spark
With big data expert and author Jeffrey Aven. Learn how to develop applications using Apache Spark. The first module in the “Big Data Development Using Apache Spark” series, this course provides a detailed overview of the spark runtime and application architecture, processing patterns, functional programming using Python, fundamental API concepts, basic programming skills and deep dives into additional constructs including broadcast variables, accumulators, and storage and lineage options. Attendees will learn to understand the Apache Spark framework and runtime architecture, fundamentals of programming for Spark, gain mastery of basic transformations, actions, and operations, and be prepared for advanced topics in Spark including streaming and machine learning.
Stream and Event Processing using Apache Spark
The second module in the “Big Data Development Using Apache Spark” series, this course provides the Spark streaming knowledge needed to develop real-time, event-driven or event-oriented processing applications using Apache Spark. It covers using Spark with NoSQL systems and popular messaging platforms like Apache Kafka and Amazon Kinesis. It covers the Spark streaming architecture in depth, and uses practical hands-on exercises to reinforce the use of transformations and output operations, as well as more advanced stream-processing patterns. With big data expert and author Jeffrey Aven.
Deep Learning and AI
This course is an introduction to the highly celebrated area of Neural Networks, popularised as “deep learning” and “AI”. The course will cover the key concepts underlying neural network technology, as well as the unique capabilities of a number of advanced deep learning technologies, including Convolutional Neural Nets for image recognition, recurrent neural nets for time series and text modelling, and new artificial intelligence techniques including Generative Adversarial Networks and Reinforcement Learning. Practical exercises will present these methods in some of the most popular Deep Learning packages available in Python, including Keras and Tensorflow. Trainees are expected to be familiar with the basics of machine learning from the Fundamentals course, as well as the python language.
Text and Language Analytics
Text analytics is a crucial skill set in nearly all contexts where data science has an impact, whether that be customer analytics, fraud detection, automation or fintech. In this course, you will learn a toolbox of skills and techniques, starting from effective data preparation and stretching right through to advanced modelling with deep-learning and neural-network approaches such as word2vec.
Forecasting and Trend Analysis
This course is an intuitive introduction to forecasting and analysis of time-series data. We will review a range of standard forecasting methods, including ARIMA and exponential smoothing, along with standard means of measuring forecast error and benchmarking with naive forecasts, and standard pre-processing/de-trending methods such as differencing and missing value imputation. Other topics will include trend/seasonality/noise decomposition, autocorrelation, visualisation of time series, and forecasting with uncertainty.
Advanced Python 1
This class builds on the introductory Python class. Jupyter Notebook advanced use and customisation is covered as well as configuring multiple environments and kernels. The Numpy package is introduced for working with arrays and matrices and a deeper coverage of Pandas data analysis and manipulation methods is provided including working with time series data. Data exploration and advanced visualisations are taught using the Plotly and Seaborne libraries.
Advanced R 1
This class builds on “Intro to R (+data visualisation)” by providing students with powerful, modern R tools including pipes, the tidyverse, and many other packages that make coding for data analysis easier, more intuitive and more readable. The course will also provide a deeper view of functional programming in R, which also allows cleaner and more powerful coding, as well as R Markdown, R Notebooks, and the shiny package for interactive documentation, browser-based dashboards and GUIs for R code.
Advanced R 2
This course goes deeper into the tidyverse family of packages, with a focus on advanced data handling, as well as advanced data structures such as list columns in tibbles, and their application to model management. Another key topic is advanced functional programming with the purrr package, and advanced use of the pipe operator. Optional topics may include dplyr on databases, and use of rmarkdown and Rstudio notebooks.
Agile Transition
This course describes the cultural and organisational aspects required for an organisation on the digital transformation path. A healthy corporate culture around data awareness is imperative to leverage the potential and value of data to the benefit of a company's business model. The organisation needs to reflect the culture and reward those who add value to a corporation by using data and analytics. Content presented explains personality and skill identification, how to prototype an agile analytics organisation and describe how to validate change capabilities, close gaps and execute a transition strategy.
Advanced Python 2
In the Advanced Python 2 course, you will learn advanced methods and packages for working with "big data" with Pandas. The course also covers using Dask for parallel computation. Machine learning is demonstrated with [...]
Advanced Machine Learning Masterclass I
This course is for experienced machine-learning practitioners who want to take their skills to the next level by using R to hone their abilities as predictive modellers. Trainees will learn essential techniques for real machine-learning model development, helping them to build more accurate models. In the masterclass, participants will work to deploy, test, and improve their models.
Advanced Machine Learning Masterclass II: Random Forest
This advanced machine learning masterclass will explore the many unique applications and extensions of the randomForest package, many of which are implemented in R. Access to the methods in random forest allows the user [...]
Understand Blockchain, Smart Contracts and Cryptocurrency
Blockchain is one of the most disruptive and least understood technologies to emerge over the previous decade. This course gives participants an intuitive understanding of blockchain in both public and private contexts, allowing them to distinguish genuine use cases from hype. We explore public crypto-currencies, smart contracts and consortium chains, interspersing theory with case studies from areas such as financial markets, health care, trade finance, and supply chain. The course does not require a technical background.
Quantum Computing
This course is an introduction to the exciting new field of quantum computing, including programming actual quantum computers in the cloud. Quantum computing promises to revolutionise cryptography, machine learning, cyber security, weather forecasting and a host of other mathematical and high-performance computing fields. A practical component will include writing quantum programs and executing them on simulators as well as on actual quantum computers in the cloud.
Advanced Deep Learning
This course provides a more rigorous, mathematically based view of modern neural networks, their training, applications, strengths and weaknesses, focusing on key architectures such as convolutional nets for image processing and recurrent nets for text and time series. This course will also include use of dedicated hardware such as GPUs and multiple computing nodes on the cloud. There will also be an overview of the most common available platforms for neural computation. Some topics touched in the introduction will be revisited in more thorough detail. Optional advanced topics may include Generative Adversarial Networks, Reinforcement Learning, Transfer Learning and probabilistic neural networks.
Advanced Fraud and Anomaly Detection
The detection of anomalies is one of the most eclectic and difficult activities in data analysis. This course builds on the basics introduced in the earlier course, and provides more advanced methods including supervised and unsupervised learning, advanced use of Benford’s Law, and more on statistical anomaly detection. Optional topics may include anomalies in time series, deception in text and the use of social network analysis to detect fraud and other undesirable behaviours.