Curricula to support your analytics function
Why have an Analytics training function?
"The most important element of a successful analytics function is neither the budget nor the caliber of the team. Nor is it the presence or even degree of C-suite “support” (often notional). Rather, it is C-suite engagement."
"Too often the C-suite is far more eager to support, fund and promote the analytics function rather than actually be its customer."
Who and what is needed for a successful analytics function?
"The most important first step of any strategic analytics review of initial implementation of a real analytics function is to determine who is already making decisions, and has a genuine need to make good ones and avoid bad ones."
"Secondly, the community of analysts/scientists, who are supporting those people with data, analysis and decision support should be identified and supported. It is vital to ally with them, make them the kernel of any new analytics function, and not to disrupt their existing work"
How do we create a successful analytics function?
"Key supporters / stakeholders need to be educated first and foremost on their role as analytics customers, not just cheerleaders."
"An effective analytics function is created top-down. Data-driven decision makers lead both by example and by making much more exacting demands of their reports for data-driven decision making, accountability and measurement."
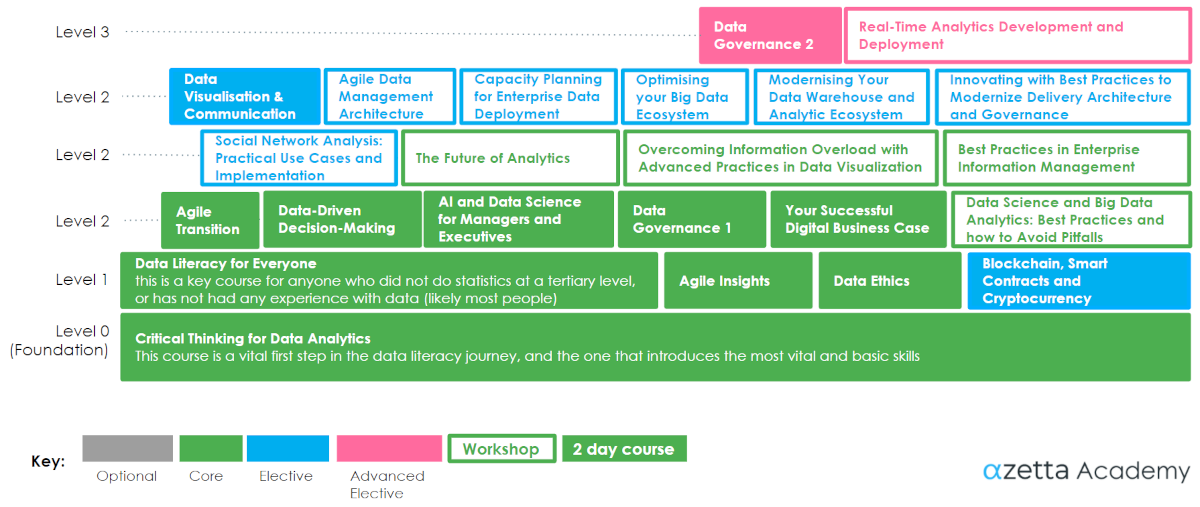
This is the minimal “data literacy” curriculum for middle and upper managers who don’t want to get too close to the actual data science work, but need to understand what it is all about, how it can benefit them, and how they might manage it. The levels build up on another, each block represents a class of two days.
Managers may also attend specialised courses such as Fraud and Anomaly Detection or Text and Language Analytics if these are relevant to their work.
{kind=link}
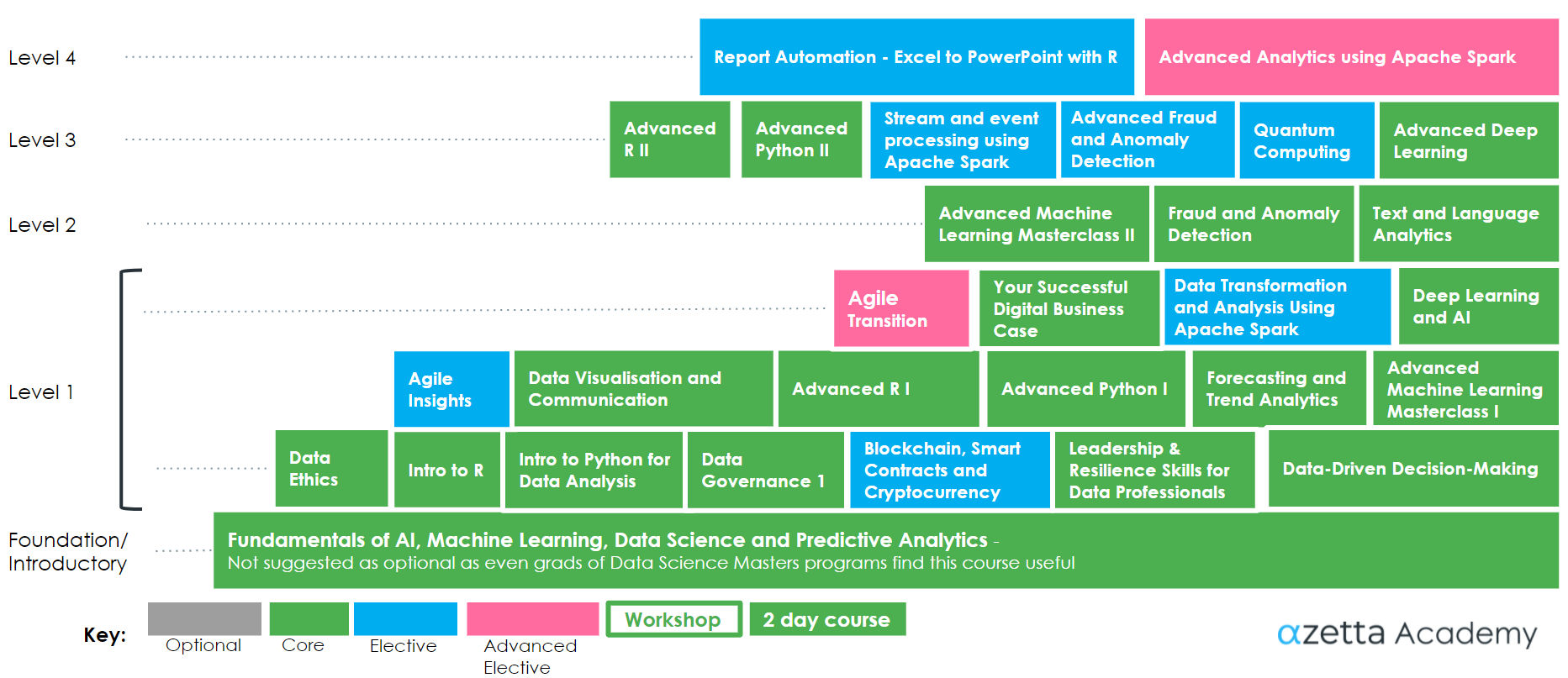
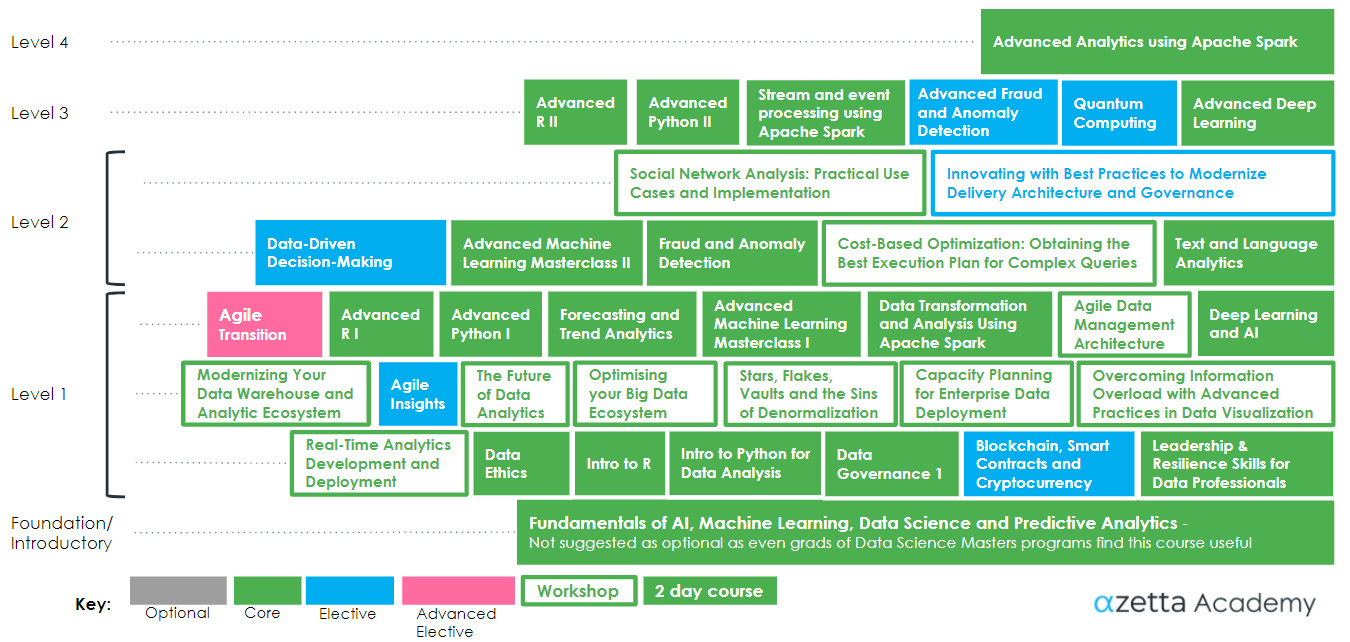
This is the course curriculum for actual or aspiring data scientists. Our Data Science Curriculum is comprehensive in its coverage of the many topics in the field. We offer starting points for all levels – from raw beginner to expert.
{kind=link}
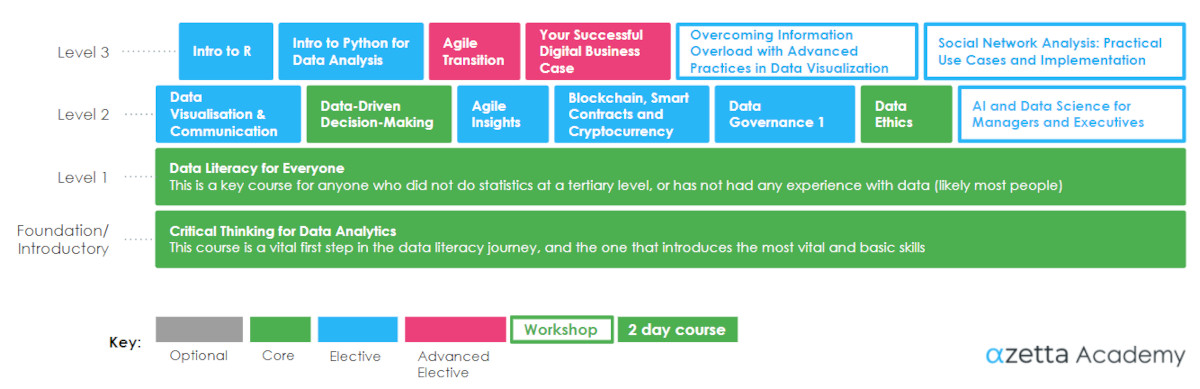
An effective data analytics strategy in any organisation needs a program to build organisational awareness around data; its ethical use, understanding, acceptance and its place in the daily conversation of what matters at all levels. Our Data Culture Curriculum focuses on literacy around data and awareness of its purpose for strategic insight.
{kind=link}
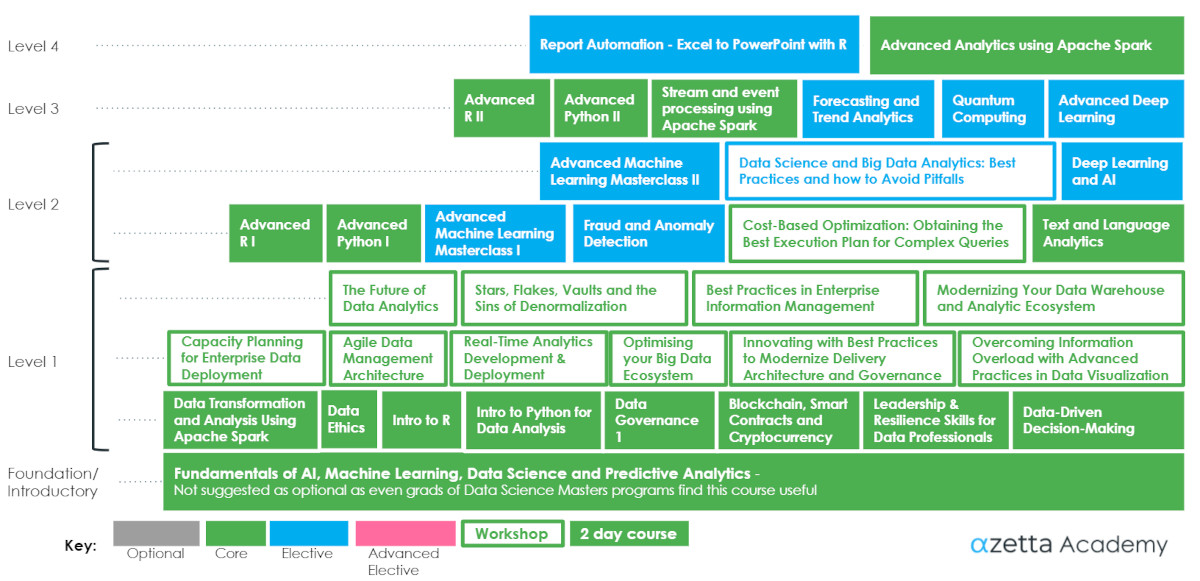
This is the curriculum for IT professionals, data analysts, data engineers, and those supporting data science.
{kind=link}
Our Data Governance Curriculum takes data culture to the next level of awareness. Those taking control or responsibility for data structures, management and ethics will gain a deeper understanding of the data governance process.
{kind=link}
A curriculum for those specialising in the automatic scaling and deployment of enterprise machine learning and artificial intelligence (AI).
{kind=link}
DevOps is redefining the IT culture. AlphaZetta member Pekka Barck has created a modular six-day training package that gives the complete picture of deploying a single DevOps step or project or planning a multi-year corporate wide strategy. The eight individual modules are loaded with practical advice, checklists, best practices and exercises. We have created the modules with development, operations and business in mind. Join us on this deep dive through the deployment pipeline to continuous integration. You get the capabilities to determine the bearing and velocity.
Enterprise digital investments carry both huge development potential for change and substantial risk of failure. This curriculum provides a baseline of essential training for staff in organisations embarking on substantial digital change, a bit like an insurance policy for digital transformation success.
Today market competition together with dramatic change demand that every organisation should become digital. Enterprises making investments in digital transformation require specific education and change programs for their staff and management in order to succeed. True digital transformation requires enterprises to be Agile while creating a strong platform as a foundation for long-term sustainable growth. Change management has therefore become an important part of the mission of many more people in an organisation than ever before. The curriculum is designed to empower all types of “change agents” with practical methods for smooth investment into digital solutions.
The curriculum has been designed by AlphaZetta member Petr Podymov, an experienced Enterprise Architect who has worked at industry pioneers of digital and Agile transformation. Petr has a focus on planning, explaining and justifying structural investments in architectural change for transformation projects. He has gained specific experience how to build and communicate business cases for architectural initiatives especially to CxO audiences.