AI Engineering Curriculum
Our AI Engineering Curriculum is for those specialising in the automatic scaling and deployment of enterprise machine learning and artificial intelligence (AI).
AlphaZetta’s workshops and courses are like none other offered in universities, online or by private providers. They are also as much a compressed mentoring experience as they are content delivery; they are not easy for an average trainer to replicate.
Contact us today to discuss how our AI Engineering Curriculum could be tailored for your organisation.
{kind=link}
*Contact us for schedule and course details
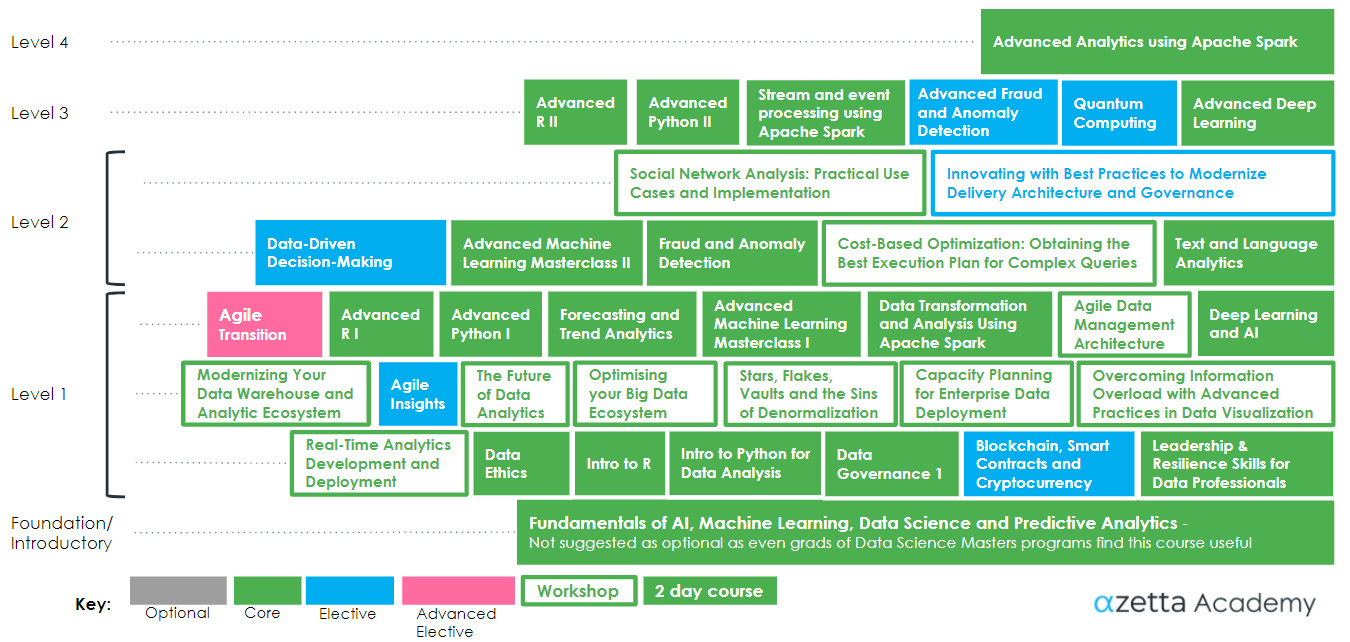
Intro to R (+ data visualisation)
This R training course will introduce you to the R programming language, teaching you to create functions and customise code so you can manipulate data and begin to use R self-sufficiently in your work. R is the world’s most popular data mining and statistics package. It’s also free, and easy to use, with a range of intuitive graphical interfaces.
Intro to Python for Data Analysis
Python is a high-level, general-purpose language used by a thriving community of millions. Data-science teams often use it in their production environments and analysis pipelines, and it’s the tool of choice for elite data-mining competition winners and deep-learning innovations. This course provides a foundation for using Python in exploratory data analysis and visualisation, and as a stepping stone to machine learning.
Fundamentals of AI, Machine Learning, Data Science and Predictive Analytics
This course is an intuitive, hands-on introduction to ai, data science and machine learning, it's your artificial intelligence 101. The training focuses on fundamentals and key skills, leaving you with a deep understanding of the core concepts of ai and data science and even some of the more advanced tools used in the field. The course does not involve coding, or require any coding knowledge or experience. As our leading course, it has transformed the artificial intelligence (AI), machine learning (ML) and data science practice of the many managers, sponsors, key stakeholders, entrepreneurs and beginning data analytics and data science practitioners who have attended it.
Data Governance I
This two day course provides an informed, realistic and comprehensive foundation for establishing best practice data governance in your organisation. Suitable for every level from CDO to executive to data steward, this highly practical course will equip you with the tools and strategies needed to successfully create and implement a data governance strategy and roadmap.
Data-Driven Decision-Making
The Data-Driven Decision-Making course is for executives and managers who want to leverage analytics to support their most vital decisions and enable better decision-making at the highest levels. It empowers senior executives with skills to make more effective use of data analytics. It covers contexts including strategic decision-making and shows attendees ways to use data to make better decisions. Attendees will learn how to receive, understand and make decisions from a range of analytics methods, including visualisation and dashboards. They will also be taught to work with analysts as effective customers.
Data Governance II
This one day course builds on the foundation of Data Governance I, and dives deeper into selected areas that are designed to provide the most practical and real-world applications of data governance. It includes the change management journey to the “data-driven” organisation, and implications of the necessity of model governance in the context of data science, AI/ML initiatives and RPA/IPA .
Advanced Analytics Using Apache Spark
With big data expert and author Jeffrey Aven. The third module in the “Big Data Development Using Apache Spark” series, this course provides the practical knowledge needed to perform statistical, machine learning and graph analysis operations at scale using Apache Spark. It enables data scientists and statisticians with experience in other frameworks to extend their knowledge to the Spark runtime environment with its specific APIs and libraries designed to implement machine learning and statistical analysis in a distributed and scalable processing environment.
Stars, Flakes, Vaults and the Sins of Denormalisation
Providing both performance and flexibility are often seen as contradictory goals in designing large scale data implementations. In this talk we will discuss techniques for denormalisation and provide a framework for understanding the performance and flexibility implications of various design options. We will examine a variety of logical and physical design approaches and evaluate the trade offs between them. Specific recommendations are made for guiding the translation from a normalised logical data model to an engineered-for-performance physical data model. The role of dimensional modeling and various physical design approaches are discussed in detail. Best practices in the use of surrogate keys is also discussed. The focus is on understanding the benefit (or not) of various denormalisation approaches commonly taken in analytic database designs.
Text and Language Analytics
Text analytics is a crucial skill set in nearly all contexts where data science has an impact, whether that be customer analytics, fraud detection, automation or fintech. In this course, you will learn a toolbox of skills and techniques, starting from effective data preparation and stretching right through to advanced modelling with deep-learning and neural-network approaches such as word2vec.
Forecasting and Trend Analysis
This course is an intuitive introduction to forecasting and analysis of time-series data. We will review a range of standard forecasting methods, including ARIMA and exponential smoothing, along with standard means of measuring forecast error and benchmarking with naive forecasts, and standard pre-processing/de-trending methods such as differencing and missing value imputation. Other topics will include trend/seasonality/noise decomposition, autocorrelation, visualisation of time series, and forecasting with uncertainty.
Advanced Python 1
This class builds on the introductory Python class. Jupyter Notebook advanced use and customisation is covered as well as configuring multiple environments and kernels. The Numpy package is introduced for working with arrays and matrices and a deeper coverage of Pandas data analysis and manipulation methods is provided including working with time series data. Data exploration and advanced visualisations are taught using the Plotly and Seaborne libraries.
Agile Insights
This course presents a process and methods for an agile analytics delivery. Agile Insights reflects the capabilities required by any organisation to develop insights from data and validate potential business value. Content presented describes the process, how it is executed and how it can be deployed as a standard process inside an organisation. The course will also share best practices, highlight potential tripwires to watch out for, as well as roles and resources required.
Advanced R 1
This class builds on “Intro to R (+data visualisation)” by providing students with powerful, modern R tools including pipes, the tidyverse, and many other packages that make coding for data analysis easier, more intuitive and more readable. The course will also provide a deeper view of functional programming in R, which also allows cleaner and more powerful coding, as well as R Markdown, R Notebooks, and the shiny package for interactive documentation, browser-based dashboards and GUIs for R code.
Advanced R 2
This course goes deeper into the tidyverse family of packages, with a focus on advanced data handling, as well as advanced data structures such as list columns in tibbles, and their application to model management. Another key topic is advanced functional programming with the purrr package, and advanced use of the pipe operator. Optional topics may include dplyr on databases, and use of rmarkdown and Rstudio notebooks.
Overcoming Information Overload with Advanced Practices in Data Visualisation
In this workshop, we explore best practices in deriving insight from vast amounts of data using visualisation techniques. Examples from traditional data as well as an in-depth look at the underlying technologies for visualisation in support of geospatial analytics will be undertaken. We will examine visualisation for both strategic and operational BI.
Advanced Python 2
In the Advanced Python 2 course, you will learn advanced methods and packages for working with "big data" with Pandas. The course also covers using Dask for parallel computation. Machine learning is demonstrated with [...]
Advanced Machine Learning Masterclass I
This course is for experienced machine-learning practitioners who want to take their skills to the next level by using R to hone their abilities as predictive modellers. Trainees will learn essential techniques for real machine-learning model development, helping them to build more accurate models. In the masterclass, participants will work to deploy, test, and improve their models.
Advanced Machine Learning Masterclass II: Random Forest
This advanced machine learning masterclass will explore the many unique applications and extensions of the randomForest package, many of which are implemented in R. Access to the methods in random forest allows the user [...]
Understand Blockchain, Smart Contracts and Cryptocurrency
Blockchain is one of the most disruptive and least understood technologies to emerge over the previous decade. This course gives participants an intuitive understanding of blockchain in both public and private contexts, allowing them to distinguish genuine use cases from hype. We explore public crypto-currencies, smart contracts and consortium chains, interspersing theory with case studies from areas such as financial markets, health care, trade finance, and supply chain. The course does not require a technical background.
Quantum Computing
This course is an introduction to the exciting new field of quantum computing, including programming actual quantum computers in the cloud. Quantum computing promises to revolutionise cryptography, machine learning, cyber security, weather forecasting and a host of other mathematical and high-performance computing fields. A practical component will include writing quantum programs and executing them on simulators as well as on actual quantum computers in the cloud.
The Future of Analytics
This full day workshop examines the trends in analytics deployment and developments in advanced technology. The implications of these technology developments for data foundation implementations will be discussed with examples in future architecture and deployment. This workshop presents best practices for deployment of a next generation data management implementation as the realization of analytic capability for mobile devices and consumer intelligence. We will also explore emerging trends related to big data analytics using content from Web 3.0 applications and other non-traditional data sources such as sensors and rich media.
Advanced Deep Learning
This course provides a more rigorous, mathematically based view of modern neural networks, their training, applications, strengths and weaknesses, focusing on key architectures such as convolutional nets for image processing and recurrent nets for text and time series. This course will also include use of dedicated hardware such as GPUs and multiple computing nodes on the cloud. There will also be an overview of the most common available platforms for neural computation. Some topics touched in the introduction will be revisited in more thorough detail. Optional advanced topics may include Generative Adversarial Networks, Reinforcement Learning, Transfer Learning and probabilistic neural networks.
Advanced Fraud and Anomaly Detection
The detection of anomalies is one of the most eclectic and difficult activities in data analysis. This course builds on the basics introduced in the earlier course, and provides more advanced methods including supervised and unsupervised learning, advanced use of Benford’s Law, and more on statistical anomaly detection. Optional topics may include anomalies in time series, deception in text and the use of social network analysis to detect fraud and other undesirable behaviours.
Innovating with Best Practices to Modernise Delivery Architecture and Governance
Organisations often struggle with the conflicting goals of both delivering production reporting with high reliability while at the same time creating new value propositions from their data assets. Gartner has observed that organizations that focus only on mode one (predictable) deployment of analytics in the construction of reliable, stable, and high-performance capabilities will very often lag the marketplace in delivering competitive insights because the domain is moving too fast for traditional SDLC methodologies. Explorative analytics requires a very different model for identifying analytic opportunities, managing teams, and deploying into production. Rapid progress in the areas of machine learning and artificial intelligence exacerbates the need for bi-modal deployment of analytics. In this workshop we will describe best practices in both architecture and governance necessary to modernise an enterprise to enable participation in the digital economy.
Modernising Your Data Warehouse and Analytic Ecosystem
This full-day workshop examines the emergence of new trends in data warehouse implementation and the deployment of analytic ecosystems. We will discuss new platform technologies such as columnar databases, in-memory computing, and cloud-based infrastructure deployment. We will also examine the concept of a “logical” data warehouse – including and ecosystem of both commercial and open source technologies. Real-time analytics and in-database analytics will also be covered. The implications of these developments for deployment of analytic capabilities will be discussed with examples in future architecture and implementation. This workshop also presents best practices for deployment of next generation analytics using AI and machine learning.
Cost-Based Optimisation: Obtaining the Best Execution Plan for Complex Queries
Optimiser choices in determining the execution plan for complex queries is a dominant factor in the performance delivery for a data foundation environment. The goal of this workshop is to de-mystify the inner workings of cost-based optimisation for complex query workloads. We will discuss the differences between rule-based optimisation and cost-based optimisation with a focus on how a cost-based optimization enumerates and selects among possible execution plans for a complex query. The influences of parallelism and hardware configuration on plan selection will be discussed along with the importance of data demographics. Advanced statistics collection is discussed as the foundational input for decision-making within the cost-based optimiser. Performance characteristics and optimiser selection among different join and indexing opportunities will also be discussed with examples. The inner workings of the query re-write engine will be described along with the performance implications of various re-write strategies.
Optimising Your Big Data Ecosystem
Big Data exploitation has the potential to revolutionise the analytic value proposition for organisations that are able to successfully harness these capabilities. However, the architectural components necessary for success in Big Data analytics are different than those used in traditional data warehousing. This workshop will provide a framework for Big Data exploitation along with recommendations for architectural deployment of Big Data solutions.
Agile Data Management Architecture
This full-day workshop examines the trends in analytic technologies, methodologies, and use cases. The implications of these developments for deployment of analytic capabilities will be discussed with examples in future architecture and implementation. This workshop also presents best practices for deployment of next generation analytics.
Social Network Analysis: Practical Use Cases and Implementation
Social networking via Web 2.0 applications such as LinkedIn and Facebook has created huge interest in understanding the connections between individuals to predict patterns of churn, influencers related to early adoption of new products and services, successful pricing strategies for certain kinds of services, and customer segmentation. We will explain how to use these advanced analytic techniques with mini case studies across a wide range of industries including telecommunications, financial services, health care, retailing, and government agencies.
Capacity Planning for Enterprise Data Deployment
This workshop describes a framework for capacity planning in an enterprise data environment. We will propose a model for defining service level agreements (SLAs) and then using these SLAs to drive the capacity planning and configuration for enterprise data solutions. Guidelines will be provided for capacity planning in a mixed workload environment involving both strategic and tactical decision support. Performance implications related to technology trends in multi-core CPU deployment, large memory deployment, and high density disk drives will be described. In addition, the capacity planning implications for different approaches for data acquisition will be considered.
Real-Time Analytics Development and Deployment
Real-time analytics is rapidly changing the landscape for deployment of decision support capability. The challenges of supporting extreme service levels in the areas of performance, availability, and data freshness demand new methods for data warehouse construction. Particular attention is paid to architectural topologies for successful implementation and the role of frameworks for Microservices deployment. In this workshop we will discuss evolution of data warehousing technology and new methods for meeting the associated service levels with each stage of evolution.