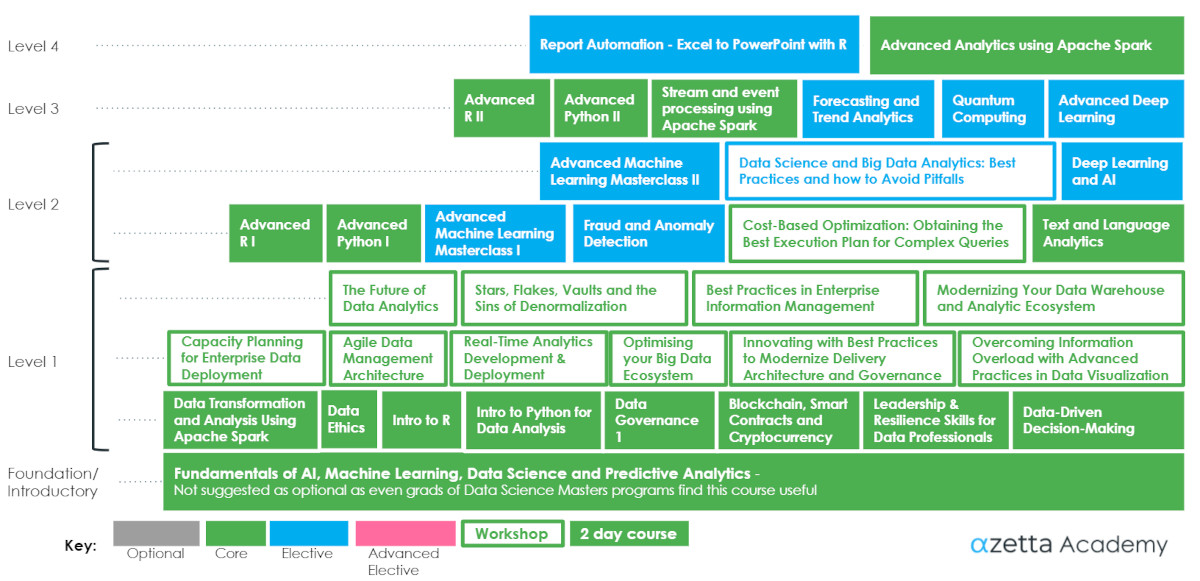
Data Engineering Curriculum
Our Data Engineering Curriculum is aimed at IT professionals, data engineers, and those supporting data science.
AlphaZetta’s workshops and courses are like none other offered in universities, online or by private providers. They are also as much a compressed mentoring experience as they are content delivery; they are not easy for an average trainer to replicate.
Contact us today to discuss how our Data Engineering Curriculum could be tailored for your organisation.
{kind=link}
*Contact us for schedule and course details
Report Automation – Excel to PowerPoint with R
Report automation can deliver powerful, time-saving results. This course teaches analytics professionals to automate the creation of PowerPoint packs from input Excel workbooks using R. Time is allotted for students to implement techniques taught so that, by the end of the course, students will have wrangled input data, created plots and tables, defined a PowerPoint template, and built a sample set of slides.
Intro to R (+ data visualisation)
This R training course will introduce you to the R programming language, teaching you to create functions and customise code so you can manipulate data and begin to use R self-sufficiently in your work. R is the world’s most popular data mining and statistics package. It’s also free, and easy to use, with a range of intuitive graphical interfaces.
Intro to Python for Data Analysis
Python is a high-level, general-purpose language used by a thriving community of millions. Data-science teams often use it in their production environments and analysis pipelines, and it’s the tool of choice for elite data-mining competition winners and deep-learning innovations. This course provides a foundation for using Python in exploratory data analysis and visualisation, and as a stepping stone to machine learning.
Fundamentals of AI, Machine Learning, Data Science and Predictive Analytics
This course is an intuitive, hands-on introduction to ai, data science and machine learning, it's your artificial intelligence 101. The training focuses on fundamentals and key skills, leaving you with a deep understanding of the core concepts of ai and data science and even some of the more advanced tools used in the field. The course does not involve coding, or require any coding knowledge or experience. As our leading course, it has transformed the artificial intelligence (AI), machine learning (ML) and data science practice of the many managers, sponsors, key stakeholders, entrepreneurs and beginning data analytics and data science practitioners who have attended it.
Data Governance I
This two day course provides an informed, realistic and comprehensive foundation for establishing best practice data governance in your organisation. Suitable for every level from CDO to executive to data steward, this highly practical course will equip you with the tools and strategies needed to successfully create and implement a data governance strategy and roadmap.
Data Science and Big Data Analytics: Leveraging Best Practices and Avoiding Pitfalls
Data science is the key to business success in the information economy. This workshop will teach you about best practices in deploying a data science capability for your organisation. Technology is the easy part; the hard part is creating the right organisational and delivery framework in which data science can be successful in your organisation. We will discuss the necessary skill sets for a successful data scientist and the environment that will allow them to thrive. We will draw a strong distinction between “Data R&D” and “Data Product” capabilities within an enterprise and speak to the different skill sets, governance, and technologies needed across these areas. We will also explore the use of open data sets and open source software tools to enable best results from data science in large organisations. Advanced data visualisation will be described as a critical component of a big data analytics deployment strategy. We will also talk about the many pitfalls and how to avoid them.
Leadership and Resilience Skills for Data Professionals
Many people today have been developed emotionally and mentally for an era that no longer really exists. This has created a critical soft-skills gap between current workforce ability and business requirements today. In this course participants learn to ‘readapt’ their soft skills so that they are aligned with a thriving 21st century business. They are also given a simple framework from which to continue the self-development so that the training instigates sustainable change.
Data-Driven Decision-Making
The Data-Driven Decision-Making course is for executives and managers who want to leverage analytics to support their most vital decisions and enable better decision-making at the highest levels. It empowers senior executives with skills to make more effective use of data analytics. It covers contexts including strategic decision-making and shows attendees ways to use data to make better decisions. Attendees will learn how to receive, understand and make decisions from a range of analytics methods, including visualisation and dashboards. They will also be taught to work with analysts as effective customers.
Data Governance II
This one day course builds on the foundation of Data Governance I, and dives deeper into selected areas that are designed to provide the most practical and real-world applications of data governance. It includes the change management journey to the “data-driven” organisation, and implications of the necessity of model governance in the context of data science, AI/ML initiatives and RPA/IPA .
Data Transformation and Analysis Using Apache Spark
With big data expert and author Jeffrey Aven. Learn how to develop applications using Apache Spark. The first module in the “Big Data Development Using Apache Spark” series, this course provides a detailed overview of the spark runtime and application architecture, processing patterns, functional programming using Python, fundamental API concepts, basic programming skills and deep dives into additional constructs including broadcast variables, accumulators, and storage and lineage options. Attendees will learn to understand the Apache Spark framework and runtime architecture, fundamentals of programming for Spark, gain mastery of basic transformations, actions, and operations, and be prepared for advanced topics in Spark including streaming and machine learning.
Stars, Flakes, Vaults and the Sins of Denormalisation
Providing both performance and flexibility are often seen as contradictory goals in designing large scale data implementations. In this talk we will discuss techniques for denormalisation and provide a framework for understanding the performance and flexibility implications of various design options. We will examine a variety of logical and physical design approaches and evaluate the trade offs between them. Specific recommendations are made for guiding the translation from a normalised logical data model to an engineered-for-performance physical data model. The role of dimensional modeling and various physical design approaches are discussed in detail. Best practices in the use of surrogate keys is also discussed. The focus is on understanding the benefit (or not) of various denormalisation approaches commonly taken in analytic database designs.
Best Practices in Enterprise Information Management
The effective management of enterprise information for analytics deployment requires best practices in the areas of people, processes, and technology. In this talk we will share both successful and unsuccessful practices in these areas. The scope of this workshop will involve five key areas of enterprise information management: (1) metadata management, (2) data quality management, (3) data security and privacy, (4) master data management, and (5) data integration.
Stream and Event Processing using Apache Spark
The second module in the “Big Data Development Using Apache Spark” series, this course provides the Spark streaming knowledge needed to develop real-time, event-driven or event-oriented processing applications using Apache Spark. It covers using Spark with NoSQL systems and popular messaging platforms like Apache Kafka and Amazon Kinesis. It covers the Spark streaming architecture in depth, and uses practical hands-on exercises to reinforce the use of transformations and output operations, as well as more advanced stream-processing patterns. With big data expert and author Jeffrey Aven.
Deep Learning and AI
This course is an introduction to the highly celebrated area of Neural Networks, popularised as “deep learning” and “AI”. The course will cover the key concepts underlying neural network technology, as well as the unique capabilities of a number of advanced deep learning technologies, including Convolutional Neural Nets for image recognition, recurrent neural nets for time series and text modelling, and new artificial intelligence techniques including Generative Adversarial Networks and Reinforcement Learning. Practical exercises will present these methods in some of the most popular Deep Learning packages available in Python, including Keras and Tensorflow. Trainees are expected to be familiar with the basics of machine learning from the Fundamentals course, as well as the python language.
Advanced Machine Learning Masterclass I
This course is for experienced machine-learning practitioners who want to take their skills to the next level by using R to hone their abilities as predictive modellers. Trainees will learn essential techniques for real machine-learning model development, helping them to build more accurate models. In the masterclass, participants will work to deploy, test, and improve their models.